


全面对标Sora 生数科技联合清华推出国内首个纯自研视频大模型
 摘要:
4月27日,在中关村论坛未来人工智能先锋论坛上,生数科技联合清华大学正式发布中国首个长时长、高一致性、高动态性视频大模型...
摘要:
4月27日,在中关村论坛未来人工智能先锋论坛上,生数科技联合清华大学正式发布中国首个长时长、高一致性、高动态性视频大模型... 4月27日,在中关村论坛未来人工智能先锋论坛上,生数科技联合清华大学正式发布中国首个长时长、高一致性、高动态性视频大模型Vidu。

据悉,该模型采用Diffusion(扩散概率模型)与Transformer融合的架构U-ViT,支持一键生成长达16秒、分辨率高达1080P的高清视频内容。生数科技方面介绍,与Sora一致,Vidu能够根据提供的文本描述直接生成长达16秒的高质量视频。
生数科技方面介绍,其核心技术U-ViT架构由团队于2022年9月提出,早于Sora采用的DiT架构,是全球首个Diffusion(扩散概率模型)与Transformer融合的架构,完全由团队自主研发。
Vidu所生成的短片,采用的是一步到位的生成方式,与Sora一样,文本到视频的转换是直接且连续的,在底层算法实现上是基于单一模型完全端到端生成,不涉及中间的插帧和其他多步骤的处理。
所谓插帧即通过在视频的每两帧画面中增加一帧或多帧来提升视频的长度或流畅度。这种方法需要对视频进行逐帧处理,通过插入额外的帧来改善视频长度和质量,是一个分步骤的过程。但Vidu与Sora则是通过单一步骤直接生成高质量的视频,无需经过多个步骤的关键帧生成和插帧处理。
2023年3月,生数科技团队开源全球首个基于U-ViT架构的多模态扩散大模UniDiffuser,在全球范围内率先完成融合架构的大规模可扩展性(Scaling Law)验证。UniDiffuser是在大规模图文数据集LAION-5B上训练出的近10亿参数量模型,支持图文模态间的任意生成和转换。在架构上,UniDiffuser比同样是DiT架构的Stable Diffusion 3领先了一年。
生数科技表示,大模型的突破是一个多维度、跨领域的综合性过程,需要技术与产业应用的深度融合。因此在发布之际,生数科技正式推出Vidu大模型合作伙伴计划,诚邀产业链上下游企业、研究机构加入,共同构建合作生态。
生数科技成立于2023年3月,公司创始团队来自清华大学人工智能研究院,是全球范围内最早从事扩散概率模型研究的团队之一。截至目前,生数科技已完成数亿元融资,投资方包括启明创投、蚂蚁集团、BV百度风投、达泰资本、锦秋基金、卓源亚洲等知名机构。
相关推荐
-
华为手机新技术将亮相!余承东发文:强悍性能超乎所见......
-
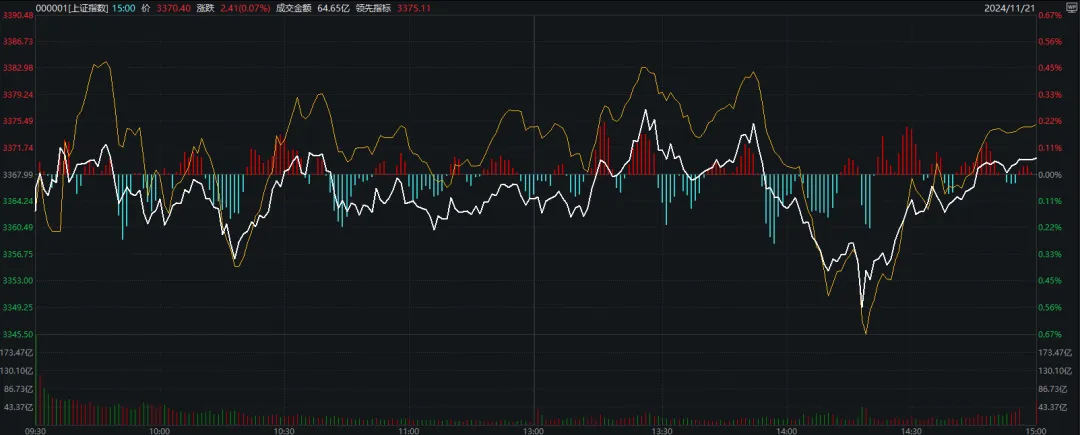
什么信号?沪指全天翻红、翻绿近20次,振幅却创近期新低
-

锁定三连阳!A500ETF基金(512050)成交额高达26.93亿元,流动性断层领先
-

A500指数ETF(560610)收涨三连阳,汤姆猫、四川长虹、三六零均涨超10%
-

楼市“止跌回稳”企业观察 | 新一轮新政助推长三角楼市复苏,龙湖旗下多个项目销售业绩“飘红”
-

再次断层领先,A500ETF基金(512050)成交额突破10亿元,居同类第一
-

寒武纪大涨逾8%再创历史新高,科创50ETF增强(588450)、双创ETF(588300)涨超1%
-

中证A500ETF成为年内“现象级”指数产品,场内热门标的A500ETF(159339)上市以来吸金逾50亿元
还没有评论,来说两句吧...