


李彦宏发布文心大模型4.0工具版 推理成本降至1年前的1%
 摘要:
4月16日,百度创始人、董事长兼首席执行官李彦宏在Create 2024百度AI开发者大会上,正式宣布发布文心大模型4....
摘要:
4月16日,百度创始人、董事长兼首席执行官李彦宏在Create 2024百度AI开发者大会上,正式宣布发布文心大模型4.... 4月16日,百度创始人、董事长兼首席执行官李彦宏在Create 2024百度AI开发者大会上,正式宣布发布文心大模型4.0的工具版。
李彦宏表示,相比一年前,文心大模型的算法训练效率提升到了原来的5.1倍,周均训练有效率达到98.8%,推理性能提升了105倍,推理的成本降到了原来的1%。也就是说,客户原来一天调用1万次,同样成本之下,现在一天可以调用100万次。
此外,李彦宏在演讲中分享了百度过去一年实践出来的、开发AI原生应用的具体思路和工具。这是我们百度根据过去一年的实践,踩了无数的坑,交了高昂的学费换来的。他强调,大语言模型本身并不直接创造价值,基于大模型开发出来的AI应用才能满足真实的市场需求。

图片来源:企业提供
李彦宏首先表示,未来,大型的AI原生应用基本都是MoE。他介绍:这里所说的MoE不是一般的学术概念,而是大小模型的混用,不依赖一个模型来解决所有问题。
其次,李彦宏表示,小模型推理成本低,响应速度快,在一些特定场景中,经过精调后的小模型使用效果可以媲美大模型。这也是百度发布ERNIE Speed、ERNIE Lite和ERNIE Tiny三个轻量模型的原因。我们通过大模型,压缩‘蒸馏’出来一个基础模型,然后再用数据去训练,这比从头开始训小模型,效果要好很多,比基于开源模型训出来的模型,效果更好,速度更快,成本更低。他表示。
第三是智能体。李彦宏表示,智能体是当前非常热的一个话题,随着智能体能力的提升,会不断催生出大量的AI原生应用。智能体机制包括理解、规划、反思和进化,它让机器像人一样思考和行动,可以自主完成复杂任务,在环境中持续学习、实现自我迭代和自我进化。在一些复杂系统中,我们还可以让不同的智能体互动,相互协作,更高质量地完成任务。这些智能体能力,我们已经开发出来了,并且向开发者全面开放。李彦宏介绍。
相关推荐
-
华为手机新技术将亮相!余承东发文:强悍性能超乎所见......
-
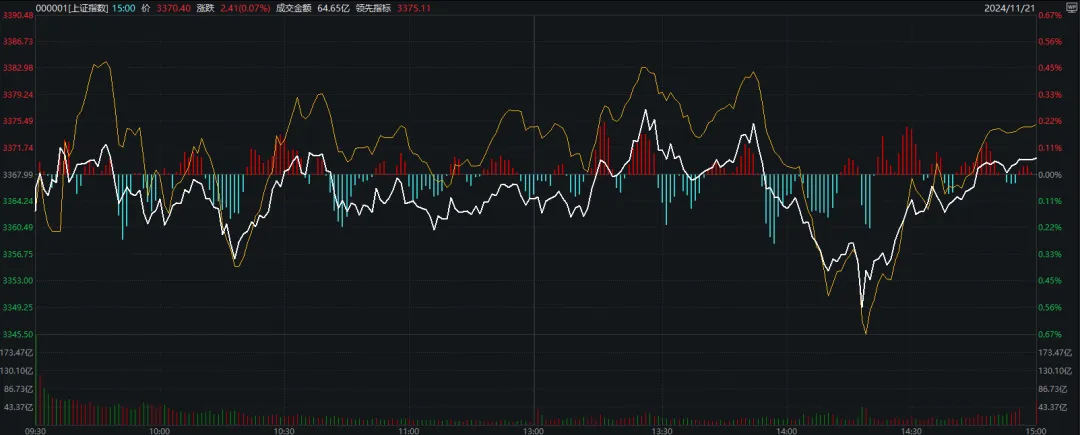
什么信号?沪指全天翻红、翻绿近20次,振幅却创近期新低
-

锁定三连阳!A500ETF基金(512050)成交额高达26.93亿元,流动性断层领先
-

A500指数ETF(560610)收涨三连阳,汤姆猫、四川长虹、三六零均涨超10%
-

楼市“止跌回稳”企业观察 | 新一轮新政助推长三角楼市复苏,龙湖旗下多个项目销售业绩“飘红”
-

再次断层领先,A500ETF基金(512050)成交额突破10亿元,居同类第一
-

寒武纪大涨逾8%再创历史新高,科创50ETF增强(588450)、双创ETF(588300)涨超1%
-

中证A500ETF成为年内“现象级”指数产品,场内热门标的A500ETF(159339)上市以来吸金逾50亿元
还没有评论,来说两句吧...